

As if being a scholar in historic Greek wasn’t laborious sufficient essentially, the first texts they depend on are ceaselessly broken past restore, being as they’re 1000’s of years outdated. Historians could have a strong new software in Ithaca, a machine studying mannequin constructed by DeepMind that makes surprisingly correct guesses at lacking phrases and the situation and date of the textual content. It’s an uncommon software of AI, however one which demonstrates how helpful it may be outdoors the tech world.
The issue of incomplete historic texts goes throughout many disciplines wherein consultants work with degraded supplies. The unique doc could be made from stone, clay or papyrus, written in Akkadian, historic Greek or Linear A, and describe something from a grocer’s invoice to a hero’s journey. What all of them have in frequent although is the harm accrued over 1000’s of years.
Gaps the place the textual content is worn or torn off are sometimes referred to as lacunae, and might be as brief as a lacking letter or so long as a chapter, or certainly a complete story. Filling them in might be trivial or unattainable, however you must begin someplace — and that’s the place Ithaca is supposed to assist.
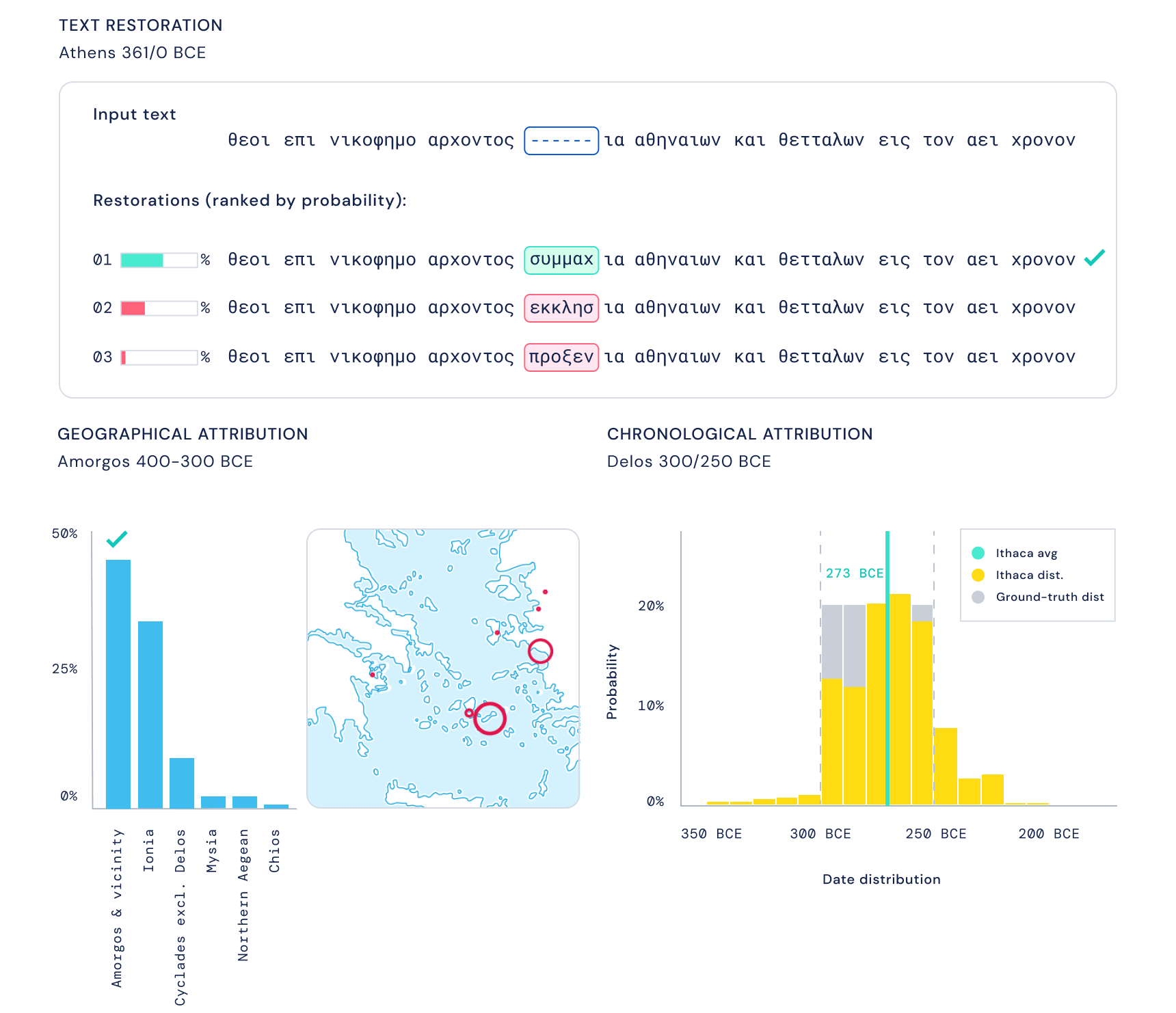
Skilled on an large library of historic Greek texts, Ithaca (named after Odysseus’s house island) not solely can say what a lacking phrase or phrase is prone to be, however can even take a shot at how outdated it’s and the place it was written. It’s not going to go filling in a complete epic cycle by itself — it’s meant to be a software for many who work with these texts, not an answer.
A paper revealed within the journal Nature demonstrates its efficacy, utilizing for example some decrees from Periclean Athens. Thought to have been written in round 445 BC, Ithaca instructed based mostly on its textual evaluation that they had been truly from 420 BC or so — consistent with more moderen proof. It may not sound like loads, however think about if the Invoice of Rights was truly written 20 years later!
Picture Credit: DeepMind
As for the textual content itself, consultants within the research obtained it about 25% proper on the primary cross; not precisely stellar, although after all textual content restoration will not be meant to be a day lark however a long-term mission. Paired with Ithaca, nonetheless, they rapidly achieved 72% accuracy. That is typically discovered to be the case in different conditions the place people in the end are extra correct however can have their course of sped up by rapidly eliminating lifeless ends or suggesting a place to begin. In medical knowledge it may be straightforward to supervise an abnormality the AI would possibly flag rapidly — however in the end it’s human experience that perceives the small print and finds the precise reply.
You’ll be able to take a look at out a pared down model of Ithaca right here, you probably have some lacunae-ridden historic Greek textual content useful, or use one in all their offered examples to see the way it fills in requested gaps. For longer items or greater than 10 letters lacking, attempt it out on this Colab pocket book. The code is offered at this GitHub web page.
Although historic Greek is an apparent and fruitful space wherein for Ithaca to begin, the group is already laborious at work on different languages as nicely. Akkadian, Demotic, Hebrew and Mayan are all on the record, and hopefully extra shall be added over time.
“Ithaca illustrates the potential contribution of pure language processing and machine studying within the humanities,” stated Ion Androutsopoulos, a professor at Athens College who labored on the mission. “We’d like extra tasks like Ithaca to additional showcase this potential, but additionally appropriate programs and instructing materials to coach future researchers who can have a greater joint understanding of each the humanities and AI strategies.”












{kind=link}